Foundations and FedAvg
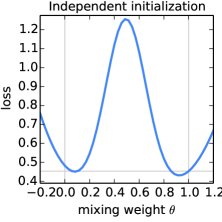
Figure: The original FedAvg paper showed that local SGD averaging can reach target accuracy in many fewer rounds than synchronized FedSGD across MNIST/CIFAR/Shakespeare. From McMahan et al., 2017 — embedded under educational fair use with attribution.
Federated learning is the training pattern where data remains on clients while models or model updates move. The usual mental picture is a server coordinating many clients: it broadcasts a current model, selected clients run local optimization, and the server aggregates the returned updates. McMahan et al. introduced this as a practical deep-learning method for decentralized mobile data and showed that local computation can reduce communication rounds by large factors compared with synchronized FedSGD [1].
The foundation matters because nearly every later federated-learning idea modifies one of four design choices: which clients participate, how much local computation they do, what they send, and how the server aggregates it. Cross-device systems emphasize massive scale, intermittent availability, and privacy-preserving aggregation. Cross-silo systems emphasize governance, auditability, higher client reliability, and institutional data sovereignty. In both cases, FedAvg is the baseline to understand before studying heterogeneity, personalization, privacy, compression, or robustness.
Definitions
Let there be clients. Client owns a local dataset with examples, and . For a model parameter vector , define the local objective
and the population-weighted federated objective
Here is the loss on example , such as cross-entropy for classification or next-token prediction. A global optimum for may not be good for every client, but it is the canonical single-model objective.
Cross-device federated learning uses very many clients, often phones, tablets, wearables, vehicles, or sensors. A client may be available only when plugged in, idle, and on unmetered networking. The server samples a small fraction of eligible clients per round, and the system expects dropouts.
Cross-silo federated learning uses fewer clients, such as hospitals, banks, labs, manufacturers, or agencies. Clients are usually more reliable, each may hold substantial data, and governance can include contracts, audit logs, certificates, and manually approved infrastructure.
FedSGD is the direct federated version of synchronous SGD. In each round, selected clients compute gradients on local data or minibatches, and the server averages those gradients before taking a global step.
FedAvg replaces one client gradient with several local SGD steps. At communication round , the server has . It samples , usually with clients for client fraction . Each selected client initializes and runs local epochs over minibatches of size :
After local training, the client sends or . The server computes
When all clients participate, this is the common formula
The basic hyperparameters are communication rounds, client fraction , local epochs , minibatch size , learning rate , and model dimension . McMahan et al. used , , and to expose the communication-computation tradeoff: more local work can dramatically reduce rounds, but too much local work can make clients drift toward incompatible local optima [1].
| Setting | Cross-device FL | Cross-silo FL |
|---|---|---|
| Typical clients | Phones, IoT, vehicles | Hospitals, banks, firms |
| Number of clients | Thousands to millions | 2 to hundreds |
| Availability | Intermittent and biased | Scheduled and reliable |
| Local data | Small per client, highly personal | Larger per silo, governed |
| Main system risk | Dropout, bandwidth, privacy | Governance, audit, trust |
| Common aggregation | Sampled synchronous rounds | Full or partial participation |
| Security emphasis | Secure aggregation, DP, abuse resistance | Access control, MPC, legal audit |
Key results
FedAvg can be read as a practical compromise between minibatch SGD and local training. With and one minibatch per selected client, it resembles FedSGD. As grows, clients spend more computation between communications, and the server receives a model that has moved along the client's local objective. If client data are IID samples from the same distribution, then local objectives are noisy approximations of , so averaging local SGD trajectories can approximate centralized SGD while requiring fewer synchronizations.
The communication win comes from doing more local work per round. McMahan et al. reported that FedAvg reduced communication rounds by roughly to times over synchronized SGD in their experimental settings, including MNIST/CIFAR-style image tasks and a Shakespeare next-character prediction task [1]. The precise speedup depends on model, data partition, learning rate, and target accuracy, but the mechanism is simple: one upload can carry the effect of many local minibatch updates.
FedAvg is not just averaging independently trained final models. All clients start a round from the same , so local models remain in a shared coordinate system. The original paper illustrates that averaging neural-network weights is much more sensible when models share initialization and training history than when independently initialized networks are averaged [1]. This point still matters in modern FL: aggregation is meaningful because local optimization is coordinated around a common global iterate.
The same design creates client drift. Under non-IID data, may point toward a local optimum that differs substantially from the optimum of . Multiple local steps compound the mismatch, so the update returned by client may no longer be an unbiased or low-variance estimate of a global descent direction. Later methods such as FedProx, SCAFFOLD, FedNova, FedBN, and MOON can all be interpreted as attempts to constrain, correct, normalize, or representationally align this drift [5], [6], [7], [11], [12].
Synchronous rounds are the cleanest baseline. In a synchronous protocol, the server waits for enough selected clients and then aggregates. This simplifies analysis and makes the round count easy to measure. Real systems add eligibility filters, deadlines, retries, secure aggregation setup, server-side optimizers, and sometimes asynchronous buffering. Bonawitz et al.'s production-system discussion emphasizes that practical FL also requires device scheduling, compression, privacy accounting, telemetry, and robust orchestration beyond the textbook algorithm [4].
FedAvg pseudocode:
initialize w_0
for t = 0, 1, ..., T-1:
m = max(floor(CK), 1)
S_t = sample m eligible clients
for each client k in S_t in parallel:
w = w_t
repeat E local epochs:
for minibatch b of size B from P_k:
w = w - eta * grad loss_b(w)
send w_{t+1}^k = w to server
w_{t+1} = sum_{k in S_t} (n_k / sum_{j in S_t} n_j) w_{t+1}^k
The important proof intuition is not that FedAvg always has a clean unbiased-gradient interpretation. Rather, in the IID limit with small local learning rates, the average of local SGD trajectories behaves like a larger minibatch stochastic update. As data become heterogeneous, higher-order terms accumulate because each client evaluates gradients at different locally moved points. This is the bridge to the heterogeneity chapter.
Visual
Worked example 1: One scalar FedAvg round
Problem. Three clients participate in one full FedAvg round. The current scalar model is . Client sizes are , , and . Each client performs local training and returns:
Compute the next global model.
Step 1: compute total selected examples.
Step 2: compute aggregation weights.
Step 3: take the weighted model average.
Checked answer. The large third client pulls the model upward. A simple unweighted average would be , but FedAvg uses data-weighted averaging, giving .
Worked example 2: Communication cost versus local computation
Problem. A model has float32 parameters. Each upload sends one model update, so each parameter costs bytes before compression. Training uses rounds, total clients, and client fraction . Compare total uplink traffic with a hypothetical FedSGD run that needs rounds using the same client fraction.
Step 1: selected clients per round.
Step 2: bytes per client upload.
Step 3: FedAvg uplink traffic.
Step 4: FedSGD uplink traffic.
Step 5: ratio.
Checked answer. If local computation lets FedAvg use rounds instead of , the uplink traffic is times smaller before considering compression or secure-aggregation overhead.
Code
import numpy as np
def fedavg_round(global_w, client_weights, client_sizes):
"""Aggregate client model vectors using FedAvg data weights."""
total = float(sum(client_sizes))
new_w = np.zeros_like(global_w, dtype=np.float64)
for w_k, n_k in zip(client_weights, client_sizes):
new_w += (n_k / total) * w_k
return new_w
def local_sgd_quadratic(w0, a, eta=0.1, steps=5):
# Minimize F_k(w) = 0.5 * (w - a)^2 on one scalar client.
w = float(w0)
for _ in range(steps):
grad = w - a
w -= eta * grad
return np.array([w])
global_w = np.array([2.0])
targets = [1.0, 2.5, 3.0]
sizes = [10, 30, 60]
local_models = [local_sgd_quadratic(global_w[0], a) for a in targets]
print([float(w[0]) for w in local_models])
print(float(fedavg_round(global_w, local_models, sizes)[0]))
Common pitfalls
- Treating federated learning as a privacy guarantee by itself; updates can still leak information.
- Averaging clients uniformly when the objective is defined with weights.
- Comparing methods by local epochs alone instead of by round count, wall-clock time, and communication.
- Forgetting that the selected-client denominator is , not always the full .
- Assuming IID convergence intuition applies under label skew, feature shift, or client-specific tasks.
- Letting grow without retuning ; local trajectories can overshoot or drift.
- Confusing cross-device and cross-silo assumptions about trust, availability, and audit requirements.
- Reporting only mean accuracy when the per-client distribution may be highly unequal.
- Ignoring downlink cost; the server also broadcasts models or compressed deltas.
- Ignoring client eligibility bias; available clients may not represent the whole population.
- Treating secure aggregation as compatible with every anomaly detector; individual updates may be hidden.
- Forgetting that real FL systems need retries, deadlines, telemetry, privacy accounting, and rollout controls.
Connections
- Optimization algorithms
- Computational performance
- Recommender systems
- Privacy-preserving data mining
- Symmetric encryption modes
- Threat models and attack taxonomy
- Heterogeneity and Federated Optimization
- Privacy: Differential Privacy and Secure Aggregation
References
[1] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, "Communication-Efficient Learning of Deep Networks from Decentralized Data," AISTATS, 2017. https://arxiv.org/abs/1602.05629
[2] P. Kairouz et al., "Advances and Open Problems in Federated Learning," Foundations and Trends in Machine Learning, 2021. https://arxiv.org/abs/1912.04977
[3] J. Konecny, H. B. McMahan, F. X. Yu, P. Richtarik, A. T. Suresh, and D. Bacon, "Federated Learning: Strategies for Improving Communication Efficiency," 2016. https://arxiv.org/abs/1610.05492
[4] K. Bonawitz et al., "Towards Federated Learning at Scale: System Design," MLSys, 2019. https://arxiv.org/abs/1902.01046
[5] T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V. Smith, "Federated Optimization in Heterogeneous Networks," MLSys, 2020. https://arxiv.org/abs/1812.06127
[6] S. P. Karimireddy, S. Kale, M. Mohri, S. J. Reddi, S. U. Stich, and A. T. Suresh, "SCAFFOLD: Stochastic Controlled Averaging for Federated Learning," ICML, 2020. https://arxiv.org/abs/1910.06378
[7] J. Wang et al., "Tackling the Objective Inconsistency Problem in Heterogeneous Federated Optimization," NeurIPS, 2020. https://arxiv.org/abs/2007.07481
[8] K. Bonawitz et al., "Practical Secure Aggregation for Privacy-Preserving Machine Learning," CCS, 2017. https://dl.acm.org/doi/10.1145/3133956.3133982
[9] M. Abadi et al., "Deep Learning with Differential Privacy," CCS, 2016. https://arxiv.org/abs/1607.00133
[10] H. B. McMahan, D. Ramage, K. Talwar, and L. Zhang, "Learning Differentially Private Recurrent Language Models," ICLR, 2018. https://arxiv.org/abs/1710.06963
[11] X. Li et al., "FedBN: Federated Learning on Non-IID Features via Local Batch Normalization," ICLR, 2021. https://openreview.net/forum?id=6YEQUn0QICG
[12] Q. Li, B. He, and D. Song, "Model-Contrastive Federated Learning," CVPR, 2021. https://arxiv.org/abs/2103.16257
[13] R. Geyer, T. Klein, and M. Nabi, "Differentially Private Federated Learning: A Client Level Perspective," 2017. https://arxiv.org/abs/1712.07557
[14] European Union, "Regulation (EU) 2016/679: General Data Protection Regulation," 2016. https://eur-lex.europa.eu/eli/reg/2016/679/oj
[15] U.S. Department of Health and Human Services, "Health Insurance Portability and Accountability Act of 1996." https://www.hhs.gov/hipaa/