Communication Efficiency and Robustness
Federated learning is constrained by communication before it is constrained by floating-point operations. A client may be able to run extra local SGD steps while idle and charging, but uploading a full neural-network update over consumer networking is expensive, slow, and energy-intensive. Communication efficiency therefore asks how to send fewer rounds, fewer parameters, fewer bits, or lower-dimensional signals without destroying convergence.
Robustness asks a different but connected question: what if some clients are malicious, compromised, or simply broken? Bagdasaryan et al. show that a malicious participant can use model replacement to inject backdoor behavior into a federated model, and that secure aggregation can make update-level anomaly detection difficult because individual updates are hidden [10]. Byzantine-robust aggregation methods such as coordinate-wise median, trimmed mean, Krum, Multi-Krum, Bulyan, FoolsGold, and FLTrust try to reduce the influence of bad updates, but their assumptions often conflict with non-IID federated data and privacy constraints [11], [12], [13], [14].
Definitions
Let a model update be . The uplink cost of uncompressed float32 communication is approximately bits per selected client per round. If clients participate for rounds, uncompressed uplink is bits, before protocol overhead.
Gradient compression reduces the number of transmitted values or bits. Top- sparsification sends only the largest-magnitude coordinates. Quantization sends low-bit approximations such as signs, ternary values, or stochastic quantized levels. Error feedback stores compression residuals locally and adds them into future updates, reducing bias.
Model compression changes the trainable or communicated model. It includes structured pruning, unstructured pruning, low-rank updates, adapters, and LoRA-style fine-tuning. In foundation models, sending only adapter or LoRA parameters can reduce communication by orders of magnitude.
Federated distillation communicates predictions, logits, prototypes, or teacher signals instead of full weights. FedMD and related methods exchange knowledge through public or proxy data distributions rather than raw private examples [7].
Lazy or event-triggered communication sends updates only when they are large or informative enough. This can save bandwidth but may bias training toward volatile clients.
Byzantine client means a client may send arbitrary updates, not just noisy gradients. A malicious client can poison labels, send random vectors, scale updates, or optimize for a backdoor.
Coordinate-wise median aggregates each coordinate by taking the median across clients. Trimmed mean removes the largest and smallest values per coordinate and averages the rest [12].
Krum selects the update closest to its neighbors. For submitted updates and assumed Byzantine bound , Krum computes
where contains the nearest other updates. The selected update has the smallest score [11].
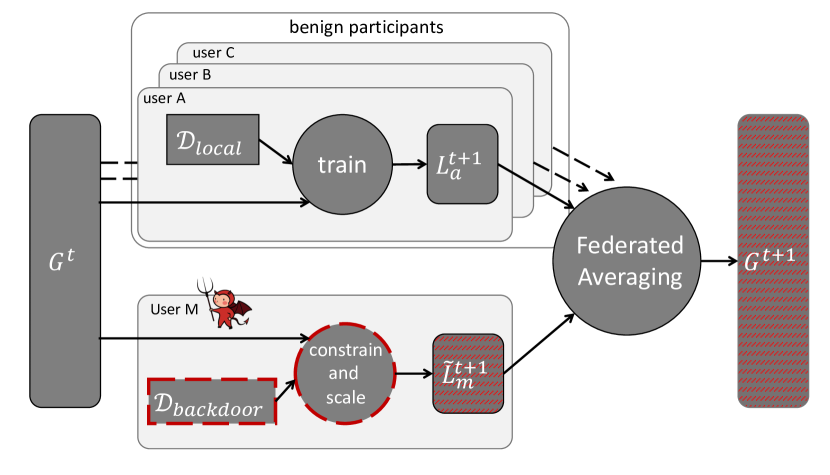
Figure: Bagdasaryan et al.'s model-replacement attack shows that a single malicious participant can implant backdoors that evade anomaly detection under secure aggregation. From Bagdasaryan et al., 2020 — embedded under educational fair use with attribution.
Model replacement is a backdoor attack where the attacker trains a malicious model and scales its submitted update so FedAvg moves the global model close to [10]. If clients are averaged uniformly in the round, an attacker can submit roughly
with near , so the aggregate is dominated by the backdoored model.
Key results
Communication efficiency has two levers: reduce the number of rounds or reduce bytes per round. FedAvg reduces rounds by using local computation [1]. Compression reduces bytes per round. These levers interact: aggressive local epochs may increase drift, and aggressive compression may add error that slows convergence. Good systems measure time-to-quality, not just bits or rounds.
Top- sparsification can be effective when gradients are heavy-tailed. A client sends indices and values for the largest coordinates. If , the values are of the dense update, but index cost matters. For large , each index may require bits. Error feedback is usually necessary because dropping coordinates forever biases the update.
Quantization reduces bits per coordinate. signSGD sends one bit per coordinate plus scale information, but the sign discards magnitude and can be vulnerable under heterogeneous gradients [4]. QSGD uses stochastic quantization with variance control [5]. TernGrad sends ternary gradients and scaling factors [6]. One-bit SGD and related approaches have a long distributed-training history, but FL adds partial participation, non-IID data, and secure aggregation constraints.
Model compression changes what is trainable. Pruning can reduce payload if the sparsity pattern is shared or cheaply encoded. Low-rank updates represent as with rank , reducing parameters from to . LoRA and adapters are especially attractive when the base model is large and fixed, as in federated fine-tuning of foundation models [16], [17]. However, low-rank aggregation is not always equivalent to averaging full updates, especially when clients use different ranks or factor orientations.
Federated distillation can avoid sending full model weights. Clients exchange logits on a public dataset, prototypes, or teacher predictions. This helps when clients use heterogeneous architectures or when model weights are too large. The cost is that the public/proxy data or shared representation must be meaningful for all clients.
Robustness methods face the non-IID problem. Coordinate-wise median and trimmed mean assume that benign updates cluster coordinate-wise. Krum assumes benign updates are closer to one another than to Byzantine updates. In federated learning, benign updates may naturally point in different directions because client data differ. A rare but legitimate hospital, language group, or device distribution can look like an outlier. This is why robust aggregation can harm fairness and personalization, and why Ditto studies fairness and robustness together [15].
Backdoor attacks are particularly dangerous because they preserve main-task accuracy. Bagdasaryan et al. show semantic backdoors in image classification and word prediction, including a constrain-and-scale technique that incorporates evasion into the attacker's training objective [10]. The attacker does not need to make the global model fail overall; it only needs the model to behave maliciously on trigger inputs.
Secure aggregation changes the defense surface. It is useful for privacy because the server should not see individual updates [9]. But many robust aggregators require individual vectors. If secure aggregation reveals only a sum, coordinate-wise median, Krum, anomaly detection, and norm filtering cannot be directly applied unless the secure protocol is redesigned to compute robust statistics privately. This is an open systems and cryptography problem, not a parameter-tuning issue.
| Technique | Saves | Main cost | Robustness interaction |
|---|---|---|---|
| More local epochs | Rounds | Client drift | Can amplify poisoned local training |
| Top- sparsification | Values sent | Index overhead, bias | Sparse malicious updates can hide in selected coordinates |
| Quantization | Bits per value | Variance, lost magnitude | Sign methods can be brittle under Byzantine signs |
| LoRA/adapters | Trainable parameters | Adapter aggregation complexity | Smaller attack surface but backdoored adapters still matter |
| Distillation | Weight traffic | Need shared proxy data | Logit poisoning possible |
| Median/trimmed mean | Byzantine influence | Coordinate-wise assumptions | Can reject rare benign clients |
| Krum/Multi-Krum | Arbitrary bad vectors | Distance assumptions | Non-IID benign updates may look malicious |
| FLTrust | Untrusted clients | Requires trusted server data | Trust anchor may be biased |
Visual
Worked example 1: Bandwidth under top-k compression
Problem. A model update has coordinates. Dense float32 upload sends bits. A top- method sends coordinates, each with a float32 value and a coordinate index. Assume each index uses bits because . There are clients per round and rounds. Compare total uplink.
Step 1: dense bits per client.
This is
Step 2: top- bits per selected coordinate.
Each coordinate sends value bits and index bits:
Step 3: top- bits per client.
Step 4: dense total uplink.
Step 5: top- total uplink.
Step 6: compression ratio.
Checked answer. Top- reduces the uplink by about times in this setup, not times, because indices are not free.
Worked example 2: Applying Krum to five client updates
Problem. Five clients send scalar updates
Assume at most Byzantine client. Krum uses nearest neighbors for each score. Compute the selected update.
Step 1: squared distances from .
To : ; to : ; to : ; to : . Two nearest are and .
Step 2: score for .
Distances: to is , to is , to is , to is . Two nearest: and .
Step 3: score for .
Distances: to is , to is , to is , to is . Two nearest: and .
Step 4: score for .
Distances: to is , to is , to is , to is . Two nearest: and .
Step 5: score for .
Distances to benign-looking updates are , , , and . Two nearest: and .
Checked answer. Krum selects either or depending on tie-breaking. It rejects the obvious malicious update . In high-dimensional non-IID FL, the benign cluster may be less clean than this toy example.
Code
import numpy as np
def topk_compress(update, k):
idx = np.argpartition(np.abs(update), -k)[-k:]
return idx, update[idx]
def krum(updates, f):
updates = np.asarray(updates, dtype=float)
n = len(updates)
neighbor_count = n - f - 2
scores = []
for i in range(n):
dists = []
for j in range(n):
if i == j:
continue
diff = updates[i] - updates[j]
dists.append(float(np.dot(diff, diff)))
scores.append(sum(sorted(dists)[:neighbor_count]))
return int(np.argmin(scores)), scores
updates = np.array([[1.0], [1.2], [0.9], [1.1], [8.0]])
winner, scores = krum(updates, f=1)
print("Krum scores:", np.round(scores, 3))
print("Selected update:", updates[winner, 0])
Common pitfalls
- Reporting compression ratio without including index, scale, mask, or protocol overhead.
- Dropping coordinates without error feedback and then blaming FedAvg for biased convergence.
- Assuming quantization errors average out under non-IID client sampling.
- Measuring bytes per round but ignoring that compression may require more rounds.
- Using top- with secure aggregation without a protocol for sparse index privacy and union handling.
- Treating LoRA communication as solved; aggregation of low-rank factors can be mathematically subtle.
- Assuming distillation works without representative public or proxy data.
- Applying Krum or median under severe non-IID data without checking false rejection of benign clients.
- Setting the Byzantine bound optimistically; too small misses attacks, too large discards signal.
- Forgetting that robust aggregation can conflict with fairness for rare client populations.
- Relying on anomaly detection while also requiring secure aggregation that hides individual updates.
- Evaluating only main-task accuracy and missing targeted backdoor success.
- Assuming norm clipping alone prevents model replacement; attackers can train within constraints.
- Ignoring adaptive attackers who know the defense and optimize around it.
Connections
- Privacy: Differential Privacy and Secure Aggregation
- Heterogeneity and Federated Optimization
- Personalization in Federated Learning
- Data poisoning and backdoors
- Certified defenses and randomized smoothing
- Gradient masking and obfuscation
- Computational performance
- Pretrained transformers for NLP
References
[1] H. B. McMahan et al., "Communication-Efficient Learning of Deep Networks from Decentralized Data," AISTATS, 2017. https://arxiv.org/abs/1602.05629
[2] J. Konecny et al., "Federated Learning: Strategies for Improving Communication Efficiency," 2016. https://arxiv.org/abs/1610.05492
[3] A. Reisizadeh, A. Mokhtari, H. Hassani, A. Jadbabaie, and R. Pedarsani, "FedPAQ: A Communication-Efficient Federated Learning Method with Periodic Averaging and Quantization," AISTATS, 2020. https://arxiv.org/abs/1909.13014
[4] J. Bernstein, Y.-X. Wang, K. Azizzadenesheli, and A. Anandkumar, "signSGD: Compressed Optimisation for Non-Convex Problems," ICML, 2018. https://arxiv.org/abs/1802.04434
[5] D. Alistarh et al., "QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding," NeurIPS, 2017. https://arxiv.org/abs/1610.02132
[6] W. Wen et al., "TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning," NeurIPS, 2017. https://arxiv.org/abs/1705.07878
[7] D. Li and J. Wang, "FedMD: Heterogenous Federated Learning via Model Distillation," 2019. https://arxiv.org/abs/1910.03581
[8] I. Itahara, T. Nishio, Y. Koda, M. Morikura, and K. Yamamoto, "Distillation-Based Semi-Supervised Federated Learning for Communication-Efficient Collaborative Training," 2020. https://arxiv.org/abs/2008.06180
[9] K. Bonawitz et al., "Practical Secure Aggregation for Privacy-Preserving Machine Learning," CCS, 2017. https://dl.acm.org/doi/10.1145/3133956.3133982
[10] E. Bagdasaryan, A. Veit, Y. Hua, D. Estrin, and V. Shmatikov, "How To Backdoor Federated Learning," AISTATS, 2020. https://arxiv.org/abs/1807.00459
[11] P. Blanchard, E. M. El Mhamdi, R. Guerraoui, and J. Stainer, "Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent," NeurIPS, 2017. https://arxiv.org/abs/1703.02757
[12] D. Yin, Y. Chen, R. Kannan, and P. Bartlett, "Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates," ICML, 2018. https://arxiv.org/abs/1803.01498
[13] E. M. El Mhamdi, R. Guerraoui, and S. Rouault, "The Hidden Vulnerability of Distributed Learning in Byzantium," ICML, 2018. https://arxiv.org/abs/1802.07927
[14] X. Cao, M. Fang, J. Liu, and N. Z. Gong, "FLTrust: Byzantine-Robust Federated Learning via Trust Bootstrapping," NDSS, 2021. https://arxiv.org/abs/2012.13995
[15] T. Li, S. Hu, A. Beirami, and V. Smith, "Ditto: Fair and Robust Federated Learning Through Personalization," ICML, 2021. https://arxiv.org/abs/2012.04221
[16] E. J. Hu et al., "LoRA: Low-Rank Adaptation of Large Language Models," ICLR, 2022. https://arxiv.org/abs/2106.09685
[17] Y. Yang et al., "Federated Low-Rank Adaptation for Foundation Models: A Survey," 2025. https://arxiv.org/abs/2505.13502
[18] P. Kairouz et al., "Advances and Open Problems in Federated Learning," Foundations and Trends in Machine Learning, 2021. https://arxiv.org/abs/1912.04977
[19] C. Xie, K. Huang, P.-Y. Chen, and B. Li, "DBA: Distributed Backdoor Attacks Against Federated Learning," ICLR, 2020. https://arxiv.org/abs/1905.10447