Pretrained Transformers and BERT
D2L moves from the Transformer architecture to large-scale pretraining because modern deep learning often starts from a pretrained model rather than from random initialization. Pretraining uses broad self-supervised tasks to learn reusable representations, then adapts those representations to downstream tasks. This shift is central to current NLP and increasingly important in vision and multimodal systems.

Figure: ELIZA provides historical context for dialogue systems and chatbot evaluation. Image: Wikimedia Commons, Unknown author, public domain text.
The chapter distinguishes encoder-only, encoder-decoder, and decoder-only Transformer families. BERT represents the encoder-only path: it builds bidirectional contextual representations through masked language modeling. Sequence-to-sequence models use encoder-decoder pretraining for tasks such as translation and summarization. Decoder-only models train autoregressively and generate text one token at a time.
Definitions
Pretraining fits a model on a broad task before the final supervised task. Fine-tuning continues training the pretrained model on task-specific data. Feature extraction freezes the pretrained model and trains only a smaller task head.
An encoder-only Transformer reads an entire input with bidirectional self-attention and produces contextual representations. BERT is the canonical example.
A decoder-only Transformer uses causal self-attention and predicts the next token:
An encoder-decoder Transformer reads a source sequence with an encoder and generates a target sequence with a decoder that attends to encoder outputs.
Masked language modeling replaces selected input tokens with a mask or corrupted token and trains the model to predict the original token from context.
Next sentence prediction, used in the original BERT formulation, asks whether two segments appeared consecutively. Later models often modify or remove this objective, but D2L uses it to explain paired-sequence pretraining.
A token embedding maps token ids to vectors. A segment embedding distinguishes sentence A from sentence B. A position embedding supplies order. BERT-style inputs sum these embeddings before the Transformer encoder.
Key results
Pretraining changes the sample-efficiency story. A task with limited labels can benefit from representations learned from much larger unlabeled corpora. This is not magic; it works when the pretraining distribution and objective teach features that transfer to the downstream task.
Masked language modeling differs from left-to-right language modeling. In MLM, the model sees both left and right context for unmasked positions, so it is well suited for understanding tasks such as classification and natural language inference. It is not directly a left-to-right generator because the training objective does not factor sequence probability autoregressively.
Fine-tuning all parameters is powerful but can overfit small datasets and requires more memory. Freezing the base model is cheaper and stable, but it may under-adapt. Parameter-efficient approaches are not the main focus of D2L, but they follow the same distinction between representation reuse and task adaptation.
For a classification task with a BERT-style encoder, a special classification token representation is often passed to a linear head:
The head is trained with cross-entropy. During full fine-tuning, gradients also update the encoder.
The family distinction matters operationally. Encoder-only models score or classify complete inputs. Encoder-decoder models transform one sequence into another. Decoder-only models are natural generators and can also solve tasks by formatting them as prompts followed by completions.
BERT-style input construction is a concrete example of how architecture and pretraining objective meet. The model receives token embeddings, segment embeddings, and positional embeddings. For sentence-pair tasks, segment ids mark which tokens belong to the first or second segment. A special classification token gives the fine-tuning head a consistent location from which to read a sequence-level representation.
Masked language modeling must avoid making the task trivial. If every selected token were always replaced by a visible mask symbol, the model would see a train-test mismatch during fine-tuning, where mask tokens usually do not appear. The original BERT recipe mixes masked replacements, random-token replacements, and unchanged selected tokens. The broader point is that the corruption process defines what information the model learns to recover.
Scaling pretrained transformers involves more than adding layers. Dataset size, tokenizer, context length, optimizer schedule, batch size, and evaluation protocol all shape the final model. D2L's taxonomy of encoder-only, encoder-decoder, and decoder-only models is a compact way to reason about which scaling path matches a task before committing compute.
Domain adaptation is a central fine-tuning question. A model pretrained on broad web text may transfer well to general sentiment analysis but less well to biomedical, legal, or code-specific tasks. Continued pretraining on in-domain unlabeled text can help before supervised fine-tuning. However, it also consumes compute and can over-specialize the model if the domain corpus is narrow.
The output interface should match the model family. Encoder-only models are natural for scoring complete inputs because every token can use both left and right context. Decoder-only models are natural for generation because causal masking matches next-token prediction. Encoder-decoder models are natural when the output is a transformed sequence conditioned on a source. Many practical design errors come from forcing a task into a poorly matched interface.
Fine-tuning also changes the representation. The pretrained model is not merely a frozen dictionary when all layers are updated; gradients from the task reshape internal features. This is powerful, but it means catastrophic overfitting or forgetting can occur when the labeled dataset is tiny or narrow.
Visual
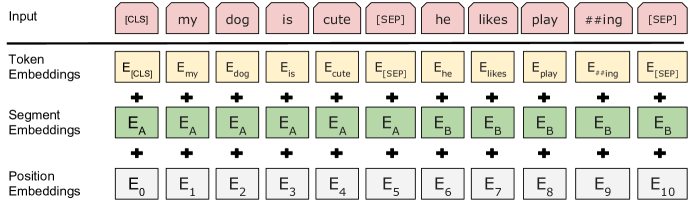
Figure: BERT input representation from Devlin et al., 2018 — embedded under educational fair use with attribution.
BERT, GPT, and T5 differ mainly in attention direction and output contract. BERT uses bidirectional encoder layers and splits into MLM plus sequence-level heads, GPT uses a causal decoder-only stack whose next-token predictions feed generation, and T5 uses an encoder memory that the causal decoder reads through cross-attention. The diagram labels the token formatting, masks, and head shapes that determine which tasks each family naturally supports.
| Transformer family | Attention direction | Pretraining objective | Best matched tasks |
|---|---|---|---|
| Encoder-only | Bidirectional | Masked token prediction | Classification, retrieval, tagging |
| Encoder-decoder | Source bidirectional, target causal | Denoising or seq2seq | Translation, summarization |
| Decoder-only | Causal | Next-token prediction | Generation, prompting |
| Vision Transformer | Patch self-attention | Supervised or self-supervised | Image classification and transfer |
Worked example 1: masked language modeling loss
Problem: a masked language model predicts two masked tokens. At the first masked position, it assigns probability to the correct token. At the second, it assigns probability . Compute the average MLM cross-entropy.
Method:
- The loss for a correct token with probability is .
- First masked token loss:
- Second masked token loss:
- Average over masked positions only:
Checked answer: the average MLM loss is about . Unmasked tokens provide context but usually do not contribute direct prediction loss.
Worked example 2: classification head dimensions
Problem: a BERT encoder returns a classification representation . A sentiment task has classes. What are the shape of the linear head and the logits for a batch of examples?
Method:
- A linear classifier maps from hidden size to class count .
- In PyTorch,
nn.Linear(768, 3)stores weight shape(3, 768)and bias shape(3). - The batch representation has shape
(32, 768). - Multiplying by the head produces
using the mathematical orientation. PyTorch stores the transposed weight internally but exposes the same result. 5. Each row of logits contains one score per sentiment class.
Checked answer: the head has trainable parameters, and the batch logits have shape (32, 3).
Code
import torch
from torch import nn
torch.manual_seed(6)
batch = 4
time = 8
vocab_size = 100
d_model = 32
classes = 3
tokens = torch.randint(0, vocab_size, (batch, time))
positions = torch.arange(time).unsqueeze(0).expand(batch, time)
segments = torch.zeros_like(tokens)
token_embed = nn.Embedding(vocab_size, d_model)
pos_embed = nn.Embedding(time, d_model)
seg_embed = nn.Embedding(2, d_model)
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=4,
dim_feedforward=128,
batch_first=True,
)
encoder = nn.TransformerEncoder(encoder_layer, num_layers=2)
classifier = nn.Linear(d_model, classes)
x = token_embed(tokens) + pos_embed(positions) + seg_embed(segments)
encoded = encoder(x)
cls_rep = encoded[:, 0, :]
logits = classifier(cls_rep)
labels = torch.randint(0, classes, (batch,))
loss = nn.CrossEntropyLoss()(logits, labels)
loss.backward()
print("logits:", logits.shape)
print("loss:", loss.item())
Common pitfalls
- Treating BERT-style masked language models as left-to-right generators.
- Fine-tuning on very small datasets without validation monitoring or regularization.
- Forgetting segment and position information when reproducing paired-input encoders.
- Computing MLM loss over every token instead of only selected prediction positions.
- Assuming larger pretrained models always transfer better under fixed compute and data constraints.
- Mixing tokenization schemes between pretraining and fine-tuning.