Modern CNNs
D2L's modern CNN chapters show how image models evolved from LeNet into deeper, more modular architectures. AlexNet demonstrated that large CNNs trained on GPUs could dominate image recognition. VGG made depth systematic through repeated small convolutional blocks. NiN and GoogLeNet introduced channel mixing and multi-branch computation. Batch normalization stabilized deep training. ResNet changed the default architecture by making identity paths explicit, and DenseNet pushed feature reuse even further.

Figure: MNIST gives classification, vision, and neural-network pages a familiar benchmark image. Image: Wikimedia Commons, Suvanjanprasai, CC BY-SA 4.0.
These models are more than a historical sequence. They introduce reusable design ideas: blocks, bottlenecks, normalization, residual connections, concatenation, global average pooling, and computational tradeoffs between width, depth, and resolution. Modern vision models still rely on these ideas even when attention or hybrid architectures are added.
Definitions
An architecture block is a repeated module with a recognizable input-output pattern. VGG blocks repeat convolutions and pooling. Inception blocks run several branches in parallel. Residual blocks add an input to a learned transformation.
AlexNet is a deep CNN that uses large early kernels, ReLU activations, dropout, and GPU training. It helped establish representation learning for large-scale image classification.
VGG uses stacks of small convolutions. Repeating small kernels increases depth and receptive field while keeping the design regular.
Network in Network uses convolutions to create per-pixel multilayer transformations over channels and replaces some fully connected classification structure with global average pooling.
GoogLeNet uses Inception blocks, where , , , and pooling branches are concatenated. convolutions often reduce channel counts before expensive convolutions.
Batch normalization normalizes intermediate activations using minibatch statistics during training and running estimates during evaluation. It learns scale and shift parameters after normalization.
ResNet uses residual blocks:
If shapes differ, a projection such as a convolution can transform before addition.
DenseNet concatenates previous feature maps:
Key results
Depth increases representational power but makes optimization harder. Residual connections help because a block can learn a residual correction around the identity. If the best transformation is close to identity, it is easier to make small than to force a plain stack of layers to learn an exact identity mapping.
Batch normalization for a scalar activation within a minibatch computes
The learned and let the network recover useful scales and offsets. Batch norm can allow larger learning rates and reduce sensitivity to initialization, but it behaves differently for small batches and sequence models.
VGG's repeated convolutions illustrate parameter tradeoffs. Two convolutions have an effective receptive field and add an extra nonlinearity. Three convolutions have an effective receptive field. This favors deeper stacks of small kernels over one large kernel in many settings.
Inception uses parallel branches because useful visual features appear at multiple scales. However, naive branches can be expensive. A bottleneck reduces the number of channels before a or convolution, cutting computation.
DenseNet's concatenation preserves earlier features instead of repeatedly transforming them by addition. This encourages feature reuse but increases channel count, so transition layers reduce spatial size and compress channels.
Batch normalization placement is a design choice, but common modern blocks use convolution, normalization, and activation as a repeated pattern. Some residual variants place normalization and activation before the convolution, creating pre-activation blocks. The practical purpose is the same: keep intermediate signals in a trainable range and make very deep networks easier to optimize.
Architecture families also reflect hardware constraints. A network with fewer parameters is not always faster if it uses operations that are inefficient on the target device. Inception reduces arithmetic with bottlenecks, VGG is regular but heavy, and residual networks offer a strong balance of accuracy and trainability. D2L's architecture tour should therefore be read as a set of design tradeoffs rather than a leaderboard.
Modern CNN design often separates the stem, stages, and head. The stem quickly maps pixels to feature maps, stages reduce resolution while increasing channels, and the head pools and classifies. This pattern makes it easier to reason about where spatial detail is lost and where semantic abstraction grows.
Residual and dense connections can be read as information-routing mechanisms. A plain deep stack forces every layer to transform the representation before passing it onward. A residual block lets information bypass a transformation by addition. A dense block lets later layers see earlier features by concatenation. These paths improve gradient flow and feature reuse, which is why they became standard components in deep vision systems.
Architecture comparison should control for training recipe. AlexNet, VGG, GoogLeNet, ResNet, and DenseNet differ in structure, but reported performance also depends on data augmentation, optimizer, learning-rate schedule, initialization, batch size, and input resolution. D2L's concise implementations are educational baselines; production comparisons need matched compute and tuned recipes.
Visual
AlexNet starts with a large stride-4 convolution that rapidly reduces the 224 x 224 image, then uses three 3 x 3 convolutions before the classifier. The diagram includes the historical channel counts, pooling transitions, and the large fully connected head where dropout was applied. It makes the compute-heavy flattening point explicit: [N, 256, 6, 6] becomes [N, 9216].
VGG is intentionally regular: each stage keeps the same spatial size inside the repeated 3 x 3 convolutions, then halves resolution with max pooling. The diagram distinguishes VGG-16 and VGG-19 by the number of convolutions in the later blocks while preserving the same 224 -> 112 -> 56 -> 28 -> 14 -> 7 spatial path. It also shows why the original classifier head is parameter-heavy after flattening 512 x 7 x 7 features.
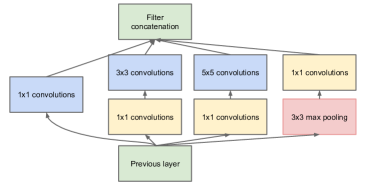
Figure: GoogLeNet's Inception module exposes the multi-branch bottleneck design used inside the network. From Szegedy et al., 2014 — embedded under educational fair use with attribution.
The Inception module runs multiple receptive-field choices in parallel while preserving the same height and width in every branch. The 1 x 1 reductions before 3 x 3 and 5 x 5 convolutions are the bottlenecks that keep the expensive branches tractable. Concatenation is along channels, so the example branch widths combine into 256 output channels.
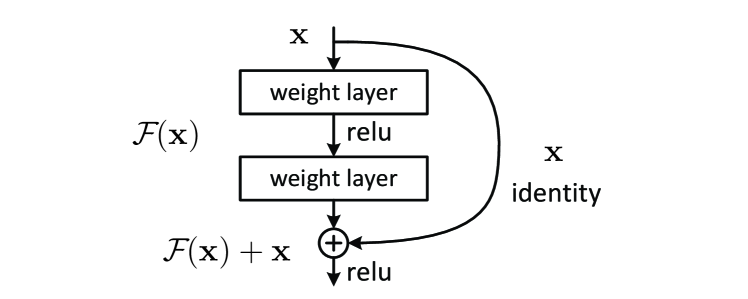
Figure: Original residual learning block from He et al., 2015 — embedded under educational fair use with attribution.
This bottleneck block shows ResNet's expansion factor of 4: the residual branch compresses with 1 x 1, processes with 3 x 3, then expands back to 4*C_mid. The shortcut is identity only when channel and spatial shapes already match; otherwise a 1 x 1 projection aligns both the channel count and stride. The addition node is the explicit residual merge.
The ResNet-50 stage diagram expands the architecture into its stem, four residual stages, and global-average-pooling head. It uses the standard ImageNet shapes: 56 x 56 for conv2_x, then 28 x 28, 14 x 14, and 7 x 7 as stages downsample. Dotted arrows mark where projection shortcuts are required because the first block of a stage changes resolution or channel count.

Figure: DenseNet architecture overview from Huang et al., 2016 — embedded under educational fair use with attribution.
DenseNet differs from ResNet by concatenating features instead of adding them. Every new layer contributes k growth-rate channels, so the dense block output channel count grows from C0 to C0+3k in this three-layer example. The transition layer then compresses channels and downsamples spatial resolution to control memory.

Figure: MobileNet's depthwise separable convolution splits spatial filtering from channel mixing to reduce computation. From Howard et al., 2017 — embedded under educational fair use with attribution.
MobileNet's depthwise-separable block splits spatial filtering from channel mixing. The depthwise convolution applies one spatial kernel per input channel, and the 1 x 1 pointwise convolution then mixes channels to produce C_out. This is the main architectural reason MobileNet blocks use far fewer parameters and multiply-adds than a dense k x k convolution.
| Family | Main design idea | Benefit | Cost or caution |
|---|---|---|---|
| AlexNet | Large CNN with ReLU and dropout | Scaled CNNs to ImageNet | Large early kernels are expensive |
| VGG | Repeated small conv blocks | Simple, regular, deep | Many parameters in classifier |
| NiN | channel MLPs | Local channel mixing | Less spatial multi-scale structure |
| GoogLeNet | Inception branches | Multi-scale features | More complex block design |
| BatchNorm | Normalize activations | Stabilizes training | Batch-size dependence |
| ResNet | Residual addition | Very deep optimization | Shape alignment required |
| DenseNet | Feature concatenation | Strong feature reuse | Channel growth |
Worked example 1: parameters saved by a bottleneck
Problem: compare the parameter count of a direct convolution from input channels to output channels with a bottleneck design that first uses a convolution from to channels, then a convolution from to channels. Ignore biases.
Method:
- Direct convolution parameters:
- Compute:
- Bottleneck parameters:
- Bottleneck parameters:
- Total bottleneck parameters:
- Reduction factor:
Checked answer: the bottleneck design uses parameters instead of , roughly a times reduction. This is why Inception-style blocks use reductions before expensive kernels.
Worked example 2: residual block shape matching
Problem: an input tensor has shape (batch, 64, 56, 56). A residual branch uses a convolutional path that outputs (batch, 128, 28, 28). Can the original input be added directly to the branch output? If not, specify a projection.
Method:
- Addition requires identical shapes, or at least broadcast-compatible shapes. Residual feature maps are meant to align elementwise, so the channel and spatial dimensions should match exactly.
- Compare channels: input has channels, branch has channels. They do not match.
- Compare height and width: input has , branch has . They do not match.
- Use a projection shortcut with output channels and stride :
- The projection changes channels from to , and stride changes spatial size from to .
Checked answer: direct addition is invalid. A convolution with stride and output channels produces a shortcut tensor of shape (batch, 128, 28, 28), which can be added to the residual branch.
Code
import torch
from torch import nn
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.body = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3,
padding=1, bias=False),
nn.BatchNorm2d(out_channels),
)
if in_channels != out_channels or stride != 1:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1,
stride=stride, bias=False),
nn.BatchNorm2d(out_channels),
)
else:
self.shortcut = nn.Identity()
self.activation = nn.ReLU()
def forward(self, x):
return self.activation(self.body(x) + self.shortcut(x))
block = ResidualBlock(64, 128, stride=2)
x = torch.randn(4, 64, 56, 56)
y = block(x)
print(y.shape)
Common pitfalls
- Adding residual tensors with mismatched channel or spatial dimensions.
- Forgetting that batch normalization has different training and evaluation behavior.
- Comparing architectures by depth alone without considering width, resolution, and compute.
- Placing global average pooling too early and destroying useful spatial detail.
- Assuming convolutions are trivial. They can dominate channel mixing and parameter counts.
- Treating named architectures as fixed recipes rather than reusable design patterns.