Perception, Object Detection, and Segmentation
Perception turns raw sensor data into scene understanding: vehicles, pedestrians, cyclists, lanes, drivable space, traffic lights, signs, cones, barriers, and free space. It is the gateway between sensing and action, but it is not a single neural network. Production stacks usually combine 2D image models, 3D lidar or radar models, tracking, map priors, temporal smoothing, uncertainty estimates, and safety monitors.
This page introduces the core perception tasks and metrics that later pages on sensor fusion, prediction, planning, and adversarial attacks build on. The main engineering theme is that perception outputs are not just labels; they are uncertain, delayed, partially observed state estimates used by downstream planners.
Definitions
Object detection localizes and classifies objects. In 2D detection, the output is usually an image bounding box and class label. In 3D detection, the output is a metric box with position, size, heading, class, and confidence in a vehicle, lidar, camera, or global coordinate frame.
Semantic segmentation assigns a class to each pixel or point, such as road, sidewalk, vehicle, vegetation, building, lane marking, or sky. It does not distinguish between separate instances of the same class.
Instance segmentation identifies separate object instances and gives each its own mask. Two adjacent pedestrians receive different instance IDs.
Panoptic segmentation combines semantic and instance segmentation. It labels every pixel or point while distinguishing countable objects, often called "things," from background regions, often called "stuff."
Lane detection estimates lane markings, lane boundaries, lane centerlines, topology, and sometimes lane connectivity through intersections. Lane perception may be image-based, map-assisted, or inferred from trajectories and drivable geometry.
Drivable-area detection estimates where the ego vehicle can physically and legally drive. It can include road surface, lane boundaries, curbs, crosswalks, construction zones, and blocked regions.
IoU, or intersection over union, measures overlap between a predicted region and a ground-truth region:
Average precision summarizes the precision-recall curve for a class. mAP averages AP across classes and often across IoU thresholds. AV benchmarks may add center-distance thresholds, heading error, velocity error, tracking metrics, or planning-aware scores.
Key results
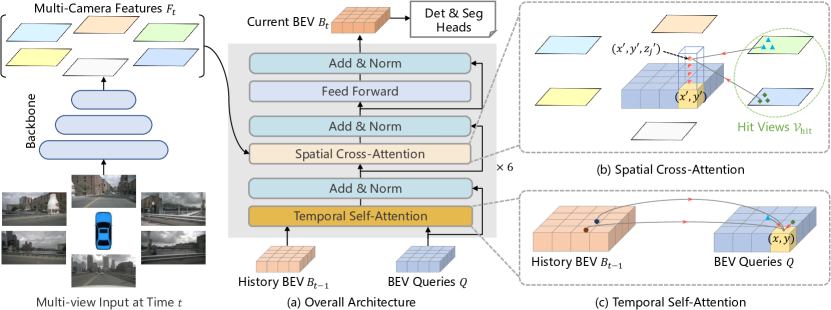
Figure: BEVFormer builds a temporal bird's-eye-view representation from multi-camera image features using transformer attention. From Li et al., 2022 — embedded under educational fair use with attribution.

Figure: DETR3D illustrates how 3D object queries are refined across detection-head layers for camera-only 3D detection. From Wang et al., 2021 — embedded under educational fair use with attribution.
Modern AV perception draws from several detector families. One-stage detectors such as YOLO and RetinaNet directly predict boxes from dense feature maps. Two-stage detectors generate proposals and refine them. Transformer-based detectors such as DETR use set prediction and bipartite matching to avoid hand-designed anchor assignment. 3D lidar detectors such as PointPillars [1] convert point clouds into pseudo-images, while CenterPoint [2] detects object centers in bird's-eye view. Camera-only 3D detection often predicts depth, lifts image features into 3D or BEV, and reasons over multiple cameras and time.
Pillar-based 3D detection
Pillar-based LiDAR detection summarizes each vertical column of a point cloud into one learned feature, then scatters those features into a BEV pseudo-image. PointPillars [1] showed that this representation can avoid expensive 3D convolution while preserving enough road-scene geometry for real-time 3D detection.
If the detection range is divided into ground-plane cells of size , a point maps to pillar indices:
Each point is decorated with local offsets before pooling, for example:
where is the mean point in pillar and is the pillar center. The pillar feature is a permutation-invariant pooled point feature:
with the max taken channelwise. After scattering to cell , a standard 2D CNN can detect oriented 3D boxes in BEV.
Compact pseudo-code:
for point in lidar_points:
cell = floor((point.xy - origin_xy) / pillar_size_xy)
pillars[cell].append(point)
for cell, points in pillars.items():
decorated = add_mean_and_center_offsets(points, cell)
feature[cell] = max_pool(shared_mlp(decorated))
bev = scatter(feature)
boxes = detection_head(backbone_2d(bev))
Worked example: with , , and , points and both fall in pillar . Their pillar mean is , so the first point's mean-centered offset is . The network sees both absolute position and local shape before it compresses the pillar.
The main tradeoff is vertical compression. Pillars are fast and well matched to road BEV reasoning, but overpasses, stacked objects, steep grades, and unusual vertical structure can be harder to represent when all height variation in one column is summarized by one feature.
Center-based 3D detection and tracking

Figure: CenterPoint reframes 3D detection and tracking around object centers instead of anchor boxes. From Yin et al., 2020 — embedded under educational fair use with attribution.
Anchor-based 3D detectors tile BEV space with many candidate boxes, sizes, and yaw priors. Center-based detectors instead predict object-center heatmaps and regress box attributes only at likely centers. CenterPoint [2] made this idea practical for LiDAR 3D detection and short-term tracking.
For each class , the detector predicts a heatmap:
whose local maxima are object centers. At a center cell it regresses:
The offsets correct feature-stride quantization, and reconstruct the 3D box, avoid the yaw discontinuity at , and velocity supports tracking. A Gaussian target around the annotated center gives smoother supervision than a single positive pixel:
Worked example: suppose the output stride is m, the grid origin is m, and a car center is m. The grid coordinates are , so the heatmap peak is at cell and the offset target is . Multiplying the offset by stride restores the metric correction m.
For short-term tracking, a detected center with predicted velocity can be projected to the previous frame:
The tracker links this projected center to a nearby previous track. This is not a full tracking theory, but it is a useful perception interface: detection, velocity, and track association all operate on the same center representation.
The precision-recall tradeoff matters more than raw accuracy. Precision is:
and recall is:
For planning, false negatives can hide real hazards, while false positives can cause unnecessary braking or stuck behavior. The best operating point depends on object type, range, speed, and maneuver. Missing a pedestrian in the lane is much worse than temporarily over-segmenting a bush near the sidewalk, but persistent false obstacles can still create unsafe traffic interactions.
3D boxes need coordinate discipline. A predicted box may be represented by center , dimensions , yaw , velocity , class , and confidence . The downstream planner needs to know the frame, timestamp, and covariance or confidence calibration. A 3D box with the right label but the wrong timestamp can be operationally wrong.
Temporal perception reduces flicker. A single frame may miss an occluded cyclist or misread a traffic light under glare. Tracking, recurrent networks, temporal transformers, and multi-frame BEV encoders allow the system to maintain hypotheses over time. Temporal smoothing, however, can also preserve stale objects after the scene changes, so deletion logic and uncertainty growth are important.
Lane and drivable-area perception are not solved by local image edges alone. Intersections, faded markings, snow, construction, reversible lanes, temporary traffic control, and emergency worker gestures often require map context, semantics, traffic rules, and behavioral reasoning.
Open-set perception is a practical requirement. The road contains objects outside a fixed label taxonomy: fallen cargo, unusual trailers, temporary barriers, animals, hand signals, flooded lanes, and damaged infrastructure. A detector may not know the exact class, but the stack still needs to represent occupancy, motion, size, and risk. Unknown-object handling is one reason occupancy and free-space estimation remain important alongside named-object detection.
Perception outputs also need lifecycle management. A detection becomes a track, a track accumulates history, and stale tracks must be deleted when evidence disappears. Deleting too aggressively causes flicker; deleting too slowly leaves phantom obstacles. This tradeoff is central to usable AV perception.
Visual

Figure: PointPillars converts sparse point clouds into pillar features before 2D convolutional detection. From Lang et al., 2019 — embedded under educational fair use with attribution.
This diagram expands perception into the standard camera, PointPillars/CenterPoint, VoxelNet, and radar branches. The key shape transition is from unordered lidar points to voxels/pillars and then to a BEV tensor, while the downstream association block turns raw detections into tracked objects and uncertainty for prediction and planning.
Worked example 1: Computing IoU for two boxes
Problem: A ground-truth 2D box spans to and to . A detector predicts to and to . Compute IoU.
- Compute ground-truth area:
- Compute predicted area:
- Compute intersection limits:
- Intersection width and height are and , so:
- Union area is:
- IoU is:
Answer: IoU is about 0.143. At a 0.5 IoU threshold this prediction is not a true positive, even though the boxes overlap visually.
Worked example 2: Precision and recall for pedestrian detection
Problem: In a validation slice, there are 20 labeled pedestrians. A detector reports 25 pedestrian boxes. Of those, 15 match true pedestrians at the required IoU threshold. Compute precision and recall.
- True positives are matched detections:
- False positives are reported boxes that do not match:
- False negatives are labeled pedestrians missed by the detector:
- Compute precision:
- Compute recall:
Answer: precision is 60 percent and recall is 75 percent.
Check: The detector found three quarters of real pedestrians but produced many extra detections. A downstream planner might tolerate extra detections at low speed but not repeated phantom braking at highway speed.
Code
import numpy as np
def box_iou_xyxy(a, b):
xa1, ya1, xa2, ya2 = a
xb1, yb1, xb2, yb2 = b
ix1, iy1 = max(xa1, xb1), max(ya1, yb1)
ix2, iy2 = min(xa2, xb2), min(ya2, yb2)
iw, ih = max(0.0, ix2 - ix1), max(0.0, iy2 - iy1)
inter = iw * ih
area_a = max(0.0, xa2 - xa1) * max(0.0, ya2 - ya1)
area_b = max(0.0, xb2 - xb1) * max(0.0, yb2 - yb1)
union = area_a + area_b - inter
return 0.0 if union == 0.0 else inter / union
def greedy_match(pred_boxes, gt_boxes, threshold=0.5):
used_gt = set()
matches = []
for i, pred in enumerate(pred_boxes):
scores = [(box_iou_xyxy(pred, gt), j) for j, gt in enumerate(gt_boxes) if j not in used_gt]
if not scores:
continue
score, j = max(scores)
if score >= threshold:
used_gt.add(j)
matches.append((i, j, score))
return matches
pred = np.array([[30, 40, 70, 80], [100, 100, 130, 160]])
gt = np.array([[10, 20, 50, 60], [98, 96, 132, 161]])
print(greedy_match(pred, gt, threshold=0.5))
Common pitfalls
- Reporting mAP without showing operating points. A planner needs thresholded behavior, not only benchmark summaries.
- Ignoring calibration of confidence scores. A detector that says 0.9 confidence should be right roughly 90 percent of the time in comparable conditions if downstream modules treat confidence probabilistically.
- Evaluating only clear-weather daytime data. Night, rain, glare, construction, unusual vehicles, and occlusion dominate safety risk.
- Treating segmentation as truth. Pixel masks can be crisp but semantically wrong, especially on reflective surfaces, shadows, snow, and road debris.
- Forgetting temporal latency. A high-quality detection that arrives too late can be worse than a noisier but timely estimate.
- Overfitting to benchmark taxonomies. Real roads contain objects outside the training label set, such as fallen cargo, temporary signs, animals, and hand gestures.
Connections
- Sensors, cameras, lidar, radar, and IMU
- Depth estimation and stereo vision
- Sensor fusion
- Prediction and motion forecasting
- Deep learning
- Adversarial attacks on AV perception
- Further reading: YOLO, RetinaNet, DETR, PointPillars, CenterPoint, Mask R-CNN, Panoptic FPN, and nuScenes or Waymo Open Dataset benchmark papers.
References
[1] A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, O. Beijbom. PointPillars: Fast Encoders for Object Detection from Point Clouds. CVPR 2019. [2] T. Yin, X. Zhou, P. Krahenbuhl. Center-based 3D Object Detection and Tracking. CVPR 2021.