Physical-World and Patch Attacks
Physical-world attacks ask whether adversarial examples survive outside a saved tensor. A perturbation must pass through printing, lighting, camera optics, viewpoint changes, compression, cropping, sensor noise, and human interpretation. Patch attacks relax the tiny-noise assumption: instead of changing every pixel a little, the adversary changes a localized region, such as a sticker, eyeglass frame, sign overlay, audio segment, or object texture.
This topic is where adversarial ML most clearly meets deployment. The correct mathematical object is no longer just ; it is a transformation pipeline from a physical modification to the model's observed input. The standard tool is expectation over transformations, and the standard warning is that digital robustness is not automatically physical robustness.
Definitions
A physical-world attack creates an adversarial effect after a real-world sensing process. If is a clean scene and is a physical perturbation, the model observes:
where represents nuisance variables such as pose, scale, lighting, camera response, background, distance, and noise.
A patch attack restricts the adversary to a region. In image coordinates, a simple digital patch model is:
where is a mask and is the patch content. The budget may be patch area, allowed location, printability, color range, or semantic plausibility rather than an norm.
An Expectation over Transformations (EOT) objective optimizes expected attack success across transformations:
For targeted attacks:
A printability constraint discourages colors or patterns that cannot be reproduced reliably by a printer or display. A semantic constraint ensures the modified object is still recognized by humans as the original object when that matters for the application.
Patch attacks can be universal or image-specific. A universal patch is optimized to fool many inputs:
Key results
The key difference between digital and physical attacks is robustness of the attack itself. A digital adversarial example may fail after a one-pixel translation or JPEG compression; a physical attack must remain effective across a distribution of transformations. EOT directly addresses this by optimizing the average loss across sampled transformations. In practice, each gradient step samples a mini-batch of transformations and backpropagates through the differentiable rendering or augmentation pipeline.
Patch attacks also show that imperceptibility is not the only threat. A patch may be obvious to a human but still dangerous if the system is expected to ignore irrelevant regions. For example, an object detector should not classify a person as a toaster because of a visible sticker. In safety settings, "visible" and "safe" are different ideas.
Physical attacks have multiple validity layers:
- Digital validity: pixel values are in range and the attack matches the simulated mask or transform.
- Manufacturing validity: the pattern can be printed, displayed, spoken, played, or fabricated.
- Sensor validity: the attack survives the camera, microphone, lidar, or other sensor pipeline.
- Task validity: humans still assign the intended class or instruction.
- Operational validity: the attacker can place, wear, display, or transmit the perturbation under deployment constraints.
Because physical evaluation is expensive, many papers use simulated EOT first and physical experiments second. The simulation does not prove physical success unless the transformation distribution matches the deployment environment. Conversely, a physical demo does not define a general robustness claim unless the scenario, attack construction, and failure cases are reported.
A careful physical report should include the full measurement protocol. For a vision system, that means object size, camera model when relevant, distance range, angle range, lighting, print or display medium, number of trials, and whether failed placements were counted. For audio, it means speakers, microphones, room conditions, loudness, background noise, and whether the perturbation survives over-the-air playback. These details are not bureaucracy: they define the distribution in the EOT objective. If is too narrow, the learned attack may be a lab artifact. If it is too broad, optimization may fail even though narrower real attacks remain possible.
Patch defenses need the same care. Cropping, blurring, JPEG compression, random resizing, or patch detectors may stop a naive patch while failing against an adaptive patch optimized through those transformations. A defense should therefore report adaptive patch optimization, not only performance against a patch generated for an undefended model.
Universal and physical attack patterns
Image-agnostic universal perturbations
Moosavi-Dezfooli et al. [1] showed that one shared perturbation vector can fool many natural images. This is a digital norm-bounded attack rather than a physical attack by itself, but it belongs in the same conceptual family as patches because one learned pattern is reused across a distribution.
The standard universal objective measures fooling rate:
under a shared budget:
The original construction loops over a dataset. If is already fooled, keep . Otherwise compute a small extra perturbation , often with a boundary method such as DeepFool, and project:
Worked micro-example: if a universal perturbation changes predictions on of held-out images, the prediction-change fooling rate is . A report must say whether the metric is prediction change or ground-truth error, because those count different failures.
Compact pseudo-code:
v = 0
for pass in dataset_passes:
for x in construction_set:
if model(x + v) still predicts model(x):
v = project(v + per_image_boundary_step(x + v), radius)
report fooling rate on held-out data
Universal perturbations are useful for studying shared decision-boundary geometry and transfer. They do not imply physical robustness unless the optimization includes print, placement, sensor, or channel transformations.
Localized universal patches
Brown et al. [2] introduced adversarial patches: visible, localized patterns optimized to dominate a classifier's prediction across images and transformations. The contribution was to shift attention from tiny imperceptible perturbations to robust artifacts that may be obvious to humans but still dangerous for a perception system expected to ignore irrelevant regions.
With mask and transformed patch , compositing is:
A targeted EOT objective is:
where samples scale, rotation, location, brightness, and other viewing variables. The patch update backpropagates through the transformation and overlay operation into the patch pixels.
Worked micro-example: a patch in a image covers:
This area budget is not comparable to an radius such as ; it describes a localized visible capability.
Compact pseudo-code:
for each optimization step:
sample images and transformations
overlay transformed patch
minimize target-class loss averaged over samples
clamp patch to valid printable values
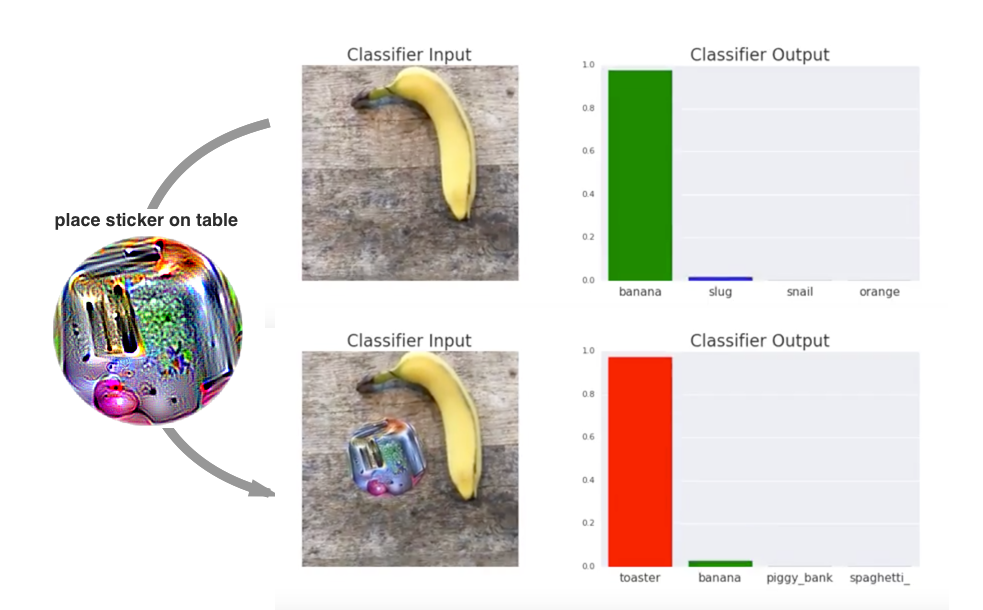
Figure: Physical adversarial patch demonstration from Brown et al., 2017 — embedded under educational fair use with attribution.
Patch reports should state area, shape, allowed locations, transformation distribution, target behavior, and whether the result is digital, printed, or physically photographed.
Robust physical road-sign markings
Eykholt et al. [3] developed robust physical perturbations for road-sign classifiers, including sticker-like and poster-like stop-sign attacks. The key contribution was not just a stop-sign demo; it was the RP2 pattern of optimizing a printable, masked perturbation over a distribution of physical viewing conditions.
For target class , an RP2-style objective is:
where includes viewpoint, scale, lighting, distance, blur, and camera effects, and regularizes visual change or printability. With a sticker mask:
Worked micro-example: if three transformed views have target losses , , and , the EOT estimate is . If and , the total objective estimate is .
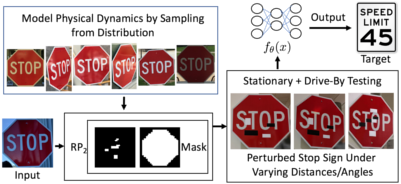
Figure: RP2 physical stop-sign attack pipeline from Eykholt et al., 2017 — embedded under educational fair use with attribution.
This attack family illustrates why physical evaluation must report distance, angle, lighting, camera, print medium, number of trials, and failed attempts. A cropped sign classifier result is not automatically a result for a full driving stack.
Visual
This diagram makes the physical patch attack loop explicit: a trainable patch is placed into many transformed scenes, passed through the real or differentiable sensor/model pipeline, and updated from the expected loss. The projection step enforces physical constraints such as printable color and patch area, while the final field-evaluation block records the real-world conditions that digital success alone cannot prove.
| Attack type | Perturbation budget | Transformation concern | Example domain |
|---|---|---|---|
| Digital norm-bounded | Usually none or light augmentation | Image classifier benchmark | |
| Sticker or patch | Area, location, color, printability | Pose, scale, lighting, occlusion | Traffic signs, object detectors |
| Wearable accessory | Shape, placement, social plausibility | Face pose, camera angle, detection crop | Face recognition |
| Audio perturbation | Loudness, psychoacoustic masking, playback channel | Room acoustics, speakers, microphones | Speech recognition |
| 3D object texture | Surface texture, material, renderer | Viewpoint, lighting, mesh geometry | 3D printed objects |
Worked example 1: EOT objective with three transformations
Problem: A targeted patch attack samples three transformations in one optimization step. The target-class cross-entropy losses are:
For a targeted attack, lower target loss is better. Compute the EOT loss estimate and explain the update direction.
- The Monte Carlo estimate of expected target loss is the average:
- Sum the losses:
- Divide by 3:
- Since the attack is targeted, the optimizer should move the patch in the negative gradient direction of this average loss:
Checked answer: the estimated EOT loss is , and a targeted gradient attack descends this average so the target class becomes more likely across transformations, not just in one view.
Worked example 2: Patch-area budget
Problem: A detector input is pixels. An attack uses a square patch of side length 80 pixels. Compute the patch area fraction.
- Image area:
- Patch area:
- Fraction:
- Simplify:
- Convert to percent:
Checked answer: the patch covers about of the image. This budget is not comparable to an budget such as ; it measures localized area rather than per-pixel amplitude.
Code
import torch
import torch.nn.functional as F
def apply_patch(x, patch, top, left):
x_patched = x.clone()
_, _, h, w = patch.shape
x_patched[:, :, top:top + h, left:left + w] = patch
return x_patched
def optimize_patch_step(model, x, y_target, patch, optimizer, transforms):
optimizer.zero_grad()
losses = []
for transform in transforms:
top, left, aug = transform
patched = apply_patch(x, patch, top, left)
viewed = aug(patched).clamp(0.0, 1.0)
losses.append(F.cross_entropy(model(viewed), y_target))
loss = torch.stack(losses).mean()
loss.backward()
optimizer.step()
with torch.no_grad():
patch.clamp_(0.0, 1.0)
return float(loss.detach())
This sketch shows the EOT pattern: apply the same learnable patch under several transformations, average the target loss, update the patch, and clamp it to a printable pixel range. Real physical attacks need a more realistic transform distribution and often a printability penalty.
Common pitfalls
- Treating digital robustness as evidence of sticker, camera, or audio robustness.
- Reporting a physical demo without the transformation range, number of trials, distances, angles, and failed attempts.
- Optimizing a patch for one fixed crop and then claiming general physical robustness.
- Ignoring human semantic validity, such as whether a modified stop sign is still a stop sign to drivers.
- Forgetting that object detectors add complications: region proposals, non-maximum suppression, confidence thresholds, and multiple objects.
- Using nondifferentiable transformations in training but not adapting the attack with approximations or score-based search.
- Comparing patch attacks to imperceptible-noise attacks without saying that their threat models are different.
Connections
- Threat models and attack taxonomy explains why physical attacks require different capability and budget definitions.
- Mathematical formulation gives the constrained-optimization view behind EOT.
- White-box attacks provides the gradient methods used inside differentiable EOT.
- Evaluation and benchmarks discusses adaptive evaluation and reporting.
- Attacks on LLMs and other modalities broadens the idea of perturbation beyond images.
Further reading
- Kurakin, Goodfellow, and Bengio, "Adversarial Examples in the Physical World."
- Athalye et al., "Synthesizing Robust Adversarial Examples."
- Eykholt et al., "Robust Physical-World Attacks on Deep Learning Visual Classification."
- Brown et al., "Adversarial Patch."
- Sharif et al., work on adversarial eyeglass frames for face recognition.
References
[1] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, P. Frossard. Universal Adversarial Perturbations. CVPR 2017. [2] T. B. Brown, D. Mane, A. Roy, M. Abadi, J. Gilmer. Adversarial Patch. arXiv 2017. [3] K. Eykholt, I. Evtimov, E. Fernandes, B. Li, A. Rahmati, C. Xiao, A. Prakash, T. Kohno, D. Song. Robust Physical-World Attacks on Deep Learning Visual Classification. CVPR 2018.